ELVIS: Enhance Low-Light for Video Instance Segmentation in the Dark
CVPR 2026
Funders: MyWorld Strength in Places
Abstract
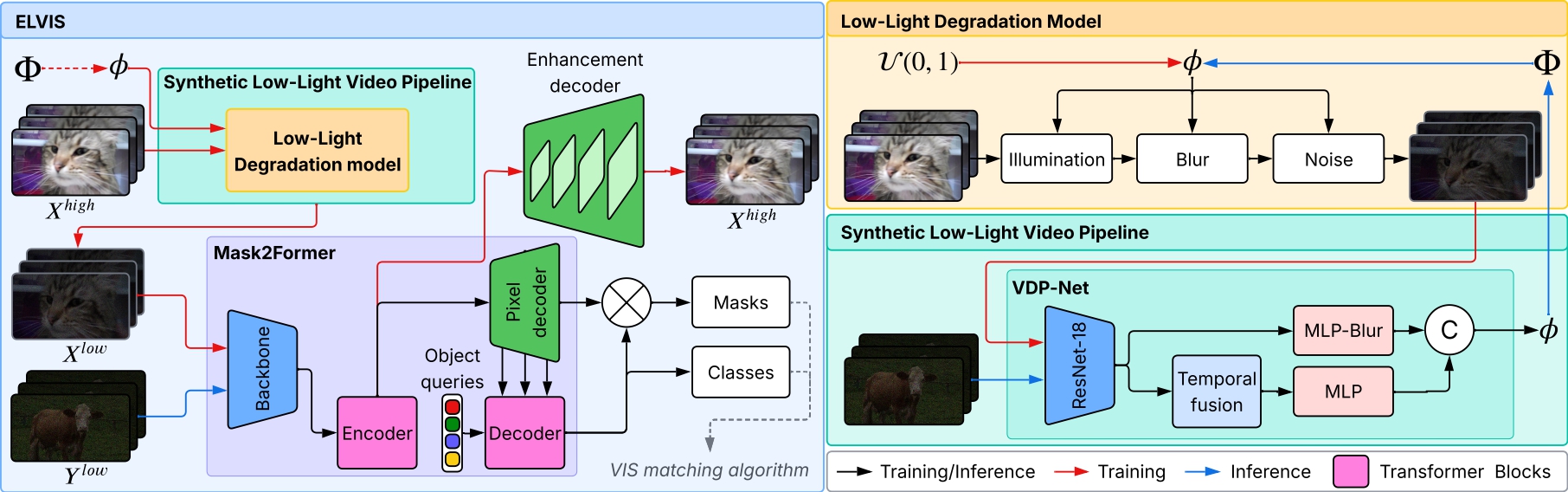
Video instance segmentation (VIS) for low-light content remains highly challenging for both humans and machines alike, due to noise, blur and other adverse conditions. The lack of large-scale annotated datasets and the limitations of current synthetic pipelines, particularly in modeling temporal degradations, further hinder progress. Moreover, existing VIS methods are not robust to the degradations found in low-light videos and, consequently, perform poorly even after finetuning. In this paper, we introduce ELVIS (Enhance Low-Light for Video Instance Segmentation), a framework that enables domain adaptation of state-of-the-art VIS models to low-light scenarios. ELVIS is comprised of an unsupervised synthetic low-light video pipeline that models both spatial and temporal degradations, a calibration-free degradation profile estimation network (VDP-Net) and an enhancement decoder head that disentangles degradations from content features. ELVIS improves performances by up to +3.7AP on the synthetic low-light YouTube-VIS 2019 dataset and beats two-stage baselines by at least +2.8AP on real low-light videos.
Video
Dataset
Download the dataset here: https://drive.google.com/drive/folders/14NSuPS0hu0kNiS4tRu7y0Mkq7cxjgVXc?usp=sharingCitation
If you use our work in your research, please cite using the following BibTeX entry:
@article{lin2026elvis,
author={Lin, Joanne and Lin, Ruirui and Li, Yini and Bull, David and Anantrasirichai, Nantheera},
title={{ELVIS}: Enhance Low-Light for Video Instance Segmentation in the Dark},
mont={June},
year={2026},
publisher={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}
}